Overview
Sometimes, during development of application, You are not able to predict what kind of data model will be best for You. It happens that process looks as follows. You start to experiment with different approaches to data model. Team is choosing one of them, first problems occurs on first complex case but You still believe that this is best solution. Application goes live! Hurrah! Everyone is happy because Go-Live went without big issues. Users start using application and generate lot of data. Your team notice that application becomes slow so You consider some modification. Team members are writing additional code to improve performance. Code is getting more and more complicated and more difficult to maintain. Next sprint planning ends with idea to change database system and approach for storing data at all. Sounds good, but we have to somehow move out existing data to new database. Team Leader is creating task for preparing data migration. But how to do it?
Scenario similar to above happens quite often. In most cases it’s migration from one data model to another but staying with same database management system. I had an opportunity to migrate data from relational database to graph database so based on this experience I’m going to show You how to do it.
When I thought about migrating data from one database to another I had in mind lot of complicated complicated queries that will help me to do this. After reading official documentation of Neo4j it found out that this much simpler than I expected. It was huge surprise for me.
Today I’m gonna show You how I processed data migration in our project which purpose is learning foreign languages.
Background
Application with translations
Together with my friend we started working on application where You can learn words from foreign languages. We decided to create flexible data model that will allow us to add words and connections between them easily without preparing SQL scripts to add new functionalities.
Additionally, because we have more than two languages, we wanted to create relations between all languages when adding simple translations. This was one of the biggest problem how to do it correctly. To explain this problem better I will use a real example from application.
Connections between words
Let’s assume that we have in database one translation from English to German: mother -> die Mutter. Now we are gonna add new one from Polish to English: matka -> mother. As we can suppose translation from Polish to German would be: matka -> die Mutter. Sounds reasonably but we don’t have connection between these two words in database. We could of course calculate it every time but this will be repeatable task and we care for performance of selecting data. That’s why we create in such case additional relation between words to have this data already prepared for fetching. This task became more complicated since we have two additional languages and two additional relation types such as synonyms and antonyms. From now we create connections not only between main words but also with theirs synonyms.
Complexity on data selection
Having such complicated model, fetching of data is also very complex. When we want to fetch all translations from one language to another we have to write big query with lot of joins. Almost always huge and complex queries causes lot of another problems and is difficult to debug and maintain.
Cure for our issues
When I started to get lost in my own code we started to think about using completely another data model. When You read above description You may notice the occurrence of word connections. Most programmers think immediately about relational database but there are much more simpler and clear approaches such as graph mode. We decided to use Neo4j. Normally this database isn’t free for commercial use but it’s free for startups so we applied it to our application and started data migration.
Relational Database Model
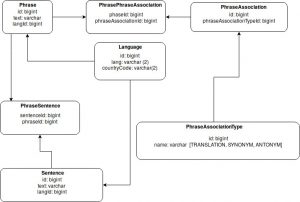
Above picture presents part of our database model. In fact it contains much more data but for our current need everything is there.
Phrase in this model is table where we store words or simple phrases in different languages (it has connection to Language table). PhraseAssociation is place where we store connections between phrases. Such association can have 3 types: TRANSLATION, SYNONYM or ANTONYM. We have also table Sentence which is container for example usages of phrases. As soon as one sentence can be example for many phrases we need to have one transition table.
For now it seems to be quite simple model. Issues occur when we add more phrases in different languages and example sentences for them. In such case when we have five languages application creates lot of associations (at least 5 times more than count of phrases). It’s noting bad in associations but in out database this means meaningless numbers (id).
Having above database model, fetching data is not so easy as You may think. Let’s consider case when we would like to fetch all translations from Polish to German.
SELECT p1.text as TEXT_FROM, l1.lang as LANG_FROM, p2.id AS ID_TO, l2.lang as LANG_TO FROM zettelchen_phrase p1 JOIN zettelchen_language l1 ON p1.lang_id = l1.id JOIN zettelchen_phrase_phrase_association zppa1 on p1.id = zppa1.phrase_id JOIN zettelchen_phrase_association zpa ON zppa1.phrase_association_id = zpa.id JOIN zettelchen_association_type zat ON zat.id = zpa.association_type_id JOIN zettelchen_phrase_phrase_association zppa2 ON zppa2.phrase_association_id = zpa.id JOIN zettelchen_phrase p2 ON zppa2.phrase_id = p2.id JOIN zettelchen_language l2 ON p2.lang_id = l2.id WHERE p1.id <> p2.id AND zat.name = 'TRANSLATION' AND (p1.text = '') IS NOT TRUE AND (p2.text = '') IS NOT TRUE AND (l1.lang = 'pl') AND (l2.lang = 'de')
We are joining only five tables to join but query becomes huge because of it’s logical complexity. Let’s see how it looks like in graph model.
Graph Model
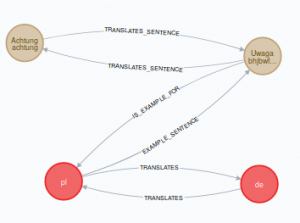
Desired model looks as follows. We have only nodes and four types of relationships. Looking at this diagram it sound to be understandable, clear and easy to use. Is it? Let’s check! We will try to fetch the same data as we would select from relational model.
MATCH (p:Phrase {lang: 'pl'})-[:TRANSLATES]->(p2:Phrase {lang: 'de'})
RETURN p.text, p.lang, p2.text, p2.lang
This query is all we need to fetch the same data as earlier.
Data migration step by step
Our application as well as databases are running on docker so below steps include operations performed on it.
1. Prepare SQL query to select data and export them to CSV file. *
Example query that is returns all translations looks as follows. We will be using parts marked in blue color in later steps.
COPY ( SELECT p1.id AS ID_FROM, p1.text as TEXT_FROM, l1.lang as LANG_FROM, p2.id AS ID_TO, p2.text as TEXT_TO, l2.lang as LANG_TO FROM zettelchen_phrase p1 JOIN zettelchen_language l1 ON p1.lang_id = l1.id JOIN zettelchen_phrase_phrase_association zppa1 on p1.id = zppa1.phrase_id JOIN zettelchen_phrase_association zpa ON zppa1.phrase_association_id = zpa.id JOIN zettelchen_association_type zat ON zat.id = zpa.association_type_id JOIN zettelchen_phrase_phrase_association zppa2 ON zppa2.phrase_association_id = zpa.id JOIN zettelchen_phrase p2 ON zppa2.phrase_id = p2.id JOIN zettelchen_language l2 ON p2.lang_id = l2.id WHERE p1.id <> p2.id AND zat.name = 'TRANSLATION' AND (p1.text = '') IS NOT TRUE AND (p2.text = '') IS NOT TRUE ) TO '/tmp/translations.csv' WITH CSV header;
Please note that when we run this query on docker container file will be stored also in container under given location.
2. Prepare CYPHER queries with usage of LOAD CSV tool to import data. *
USING PERIODIC COMMIT LOAD CSV WITH HEADERS FROM 'file:/translations.csv' AS row MERGE (from:Phrase { externalId: row.id_from }) ON CREATE SET from.uuid = randomUUID(), from.text = row.text_from, from.lang = row.lang_from MERGE (to:Phrase { externalId: row.id_to }) ON CREATE SET to.uuid = randomUUID(), to.text = row.text_to, to.lang = row.lang_to MERGE (from)-[r:TRANSLATES { code: row.lang_from + '-' + row.lang_to }]->(to);
As You can see we get all values from csv file and read them line by line creating new nodes and relationships. I also colored some fields to show that we are using the same fields that we exported earlier. CSV file should be place in import directory, You can name it import.cypher.
3. Run script from first step on postgres
To be able to export our data we can use psql. This simple command loads given file and runs it. We can call it from outside of docker container but exported file will be generated inside.
psql -h $POSTGRES_HOST -p $POSTGRES_PORT -U $POSTGRES_USER -d $POSTGRES_DB < export_csv.sql
4 .Get exported csv files from postgres container.
docker cp $POSTGRES_CONTAINER_ID:/tmp/translations.csv translations.csv
Hint: If you want to get POSTGRES_CONTAINER_ID use this command:
docker ps -aqf "name=$POSTGRES_CONTAINER_NAME"
5. Move exported csv files to neo4j container to “import” directory
docker cp translations.csv $NEO4J_CONTAINER_ID:/import/translations.csv
6. Move script prepared in step 2 also to this docker container but to /tmp directory
docker cp import_csv.cypher $NEO4J_CONTAINER_ID:/tmp/import_csv.cypher
7. Use cypher-shell tool with prepared script as input. *
Prepare shell script with below command and than copy it in same way like we copied file in step 6.
USERNAME=$1 PASSWORD=$2 cat /tmp/import_csv.cypher | /var/lib/neo4j/bin/cypher-shell -u $USERNAME -p $PASSWORD
Now we can run out script on docker using exec command:
docker exec $NEO4J_CONTAINER_NAME /tmp/$YOUR_SHELL_SCRIPT.sh $USERNAME $PASSWORD
Operation should end up with Success message, in other case You will see meaningful error message on console. To see more detailed message You can add flags –debug –format verbose to cypher-shell.
8. Remove temporary files.
In this step we only check if file exists and remove it.
if [ -f translations.csv ] ; then rm translations.csv fi
* – steps marked with asterisk are required in process of data migration. Rest of steps are connected with docker infrastructure that I prepared on my machine. It means that we have to do only 3 simple steps to make it fully functional.
Summary
As You can see data migration is all about export data in desired format and import them using respective query language. Thanks to LOAD CSV command process of moving data from one database to another is pretty simple. Neo4j, as I wrote in previous post, represents real relations between data. In some cases it is much more better than classic approach with relational database. In case of our application step towards the graph database has proved to be perfect choice. Now application’s code is much more cleaner and simpler. Thanks to graph algorithms, speed of fetching data has also increased.
I found graph approach very useful and friendly, that’s why I recommend all reading once again requirements of Your application because maybe in Your case Neo4j will also be useful.
Thanks for reading. If You have any question regarding aforementioned topic don’t hesitate to ask me on Facebook, LinkedIn or via mail [email protected].
About author

Hi,
my name is Michał. I’m software engineer. I like sharing my knowledge and ideas to help other people who struggle with technologies and design of todays IT systems or just want to learn something new.
If you want to be up to date leave your email below or leave invitation on LinkedIn, XING or Twitter.


